وقتی «نه» یعنی «آره»/ چرا هوش مصنوعی از درک تعارف عاجز است؟

تینا مزدکی_همه ما ایرانیها میدانیم که اگر یک راننده تاکسی بگوید «کرایه این دفعه را مهمان من باشید» و مسافر قبول کند، یک اشتباه رخ داده است. در واقع آنچه یاد گرفتهایم این است که نهایتا بعد از دو یا سه بار اصرار کردن باید کرایه خود را بپردازیم و این تنها بخشی از تعارفهای روزمره فرهنگ ما است. دقیقا همان چیزی که مدلهای هوش مصنوعی در درک آن به شدت ناتوان هستند.
پژوهش تازهای اوایل ماه جاری منتشر شده و عنوان آن «ما محترمانه اصرار میکنیم: مدلهای زبانی شما، باید هنر فارسی تعارف را بیاموزند» است. این پژوهش نشان میدهد که مدلهای زبانی متداول شرکتهای OpenAI، آنتروپیک و متا در درک این فرهنگ اجتماعی فارسی ناکام ماندهاند و تنها در ۳۴ تا ۴۲ درصد موارد توانستهاند موقعیتهای تعارف را بهدرستی مدیریت کنند، این در حالی است که افرادی که به زبان فارسی صحبت میکنند، در ۸۲ درصد موارد، عملکرد درست داشتهاند.
در پژوهشی که به سرپرستی نیکتا گوهریصدر از دانشگاه براک انجام شد، چارچوبی به نام «TAAROFBENCH» معرفی شده است که نخستین شاخص برای سنجش میزان توانایی سیستمهای هوش مصنوعی در بازتولید این آیین فرهنگی پیچیده است. یافتههای پژوهشگران نشان میدهد که مدلهای هوش مصنوعی طور پیشفرض به سبک مستقیم حرف زدنهای غربی گرایش دارند و هیچ توجهی به نشانههای فرهنگیای که تعاملات روزمره میلیونها فارسیزبان در سراسر جهان را شکل میدهد ندارند.
محققان میگویند بیتوجهی به فرهنگ در موقعیتهای حساس میتواند مذاکرات را به شکست بکشاند، روابط را تخریب و کلیشهها را تقویت کند. برای سیستمهای هوش مصنوعی که روزبهروز بیشتر در بسترهای جهانی به کار گرفته میشوند، نادیده گرفتن چنین فرهنگی میتواند به محدودیتی تبدیل شود که تنها درصد کمی از مردمان غرب با آن آشنا هستند. تعارف، یکی از عناصر اصلی ادب فارسی، بخشی از ادب آیینی است که در آن آنچه گفته میشود اغلب با آنچه منظور است تفاوت دارد.
تعارف در قالب مبادلات آیینی نمود پیدا میکند، در آن به طور مکرر پیشنهاد داده میشود و فرد مقابل، دائم امتناع میکند. درست مانند هدیه دادن که در آن فردی هدیه میدهد و فرد دیگر هدیه را پس میزند و این چرخه پیشنهاد و امتناع دوباره تکرار میشود. این داد و ستد کلامی، نوعی رقص ظریف از اصرار و مقاومت است که تعاملات روزمره در فرهنگ ایرانی را شکل میدهد و قواعد ضمنی برای چگونگی ابراز سخاوت، قدردانی و درخواستها ایجاد میکند.
ادب وابسته به پیشینه است
برای سنجش اینکه آیا «مودب بودن» بهتنهایی برای شایستگی فرهنگی کافی است یا نه، پژوهشگران پاسخهای مدل Llama ۳ را با استفاده از Polite Guard (معیاری توسعهیافته توسط اینتل که میزان ادب متن را ارزیابی میکند) مورد مقایسه قرار دادند. نتایج تناقض داشتند و در حالی که ۸۴.۵ درصد از پاسخها بهعنوان «مودب» یا «تاحدی مودب» ثبت شدند، تنها ۴۱.۷ درصد از همان پاسخها واقعاً با انتظارات فرهنگی فارسی در موقعیتهای تعارف سازگار بودند.
این شکاف ۴۲.۸ واحد درصدی نشان میدهد که یک پاسخ از سوی مدل زبانی بزرگ میتواند همزمان در یک زمینه مودبانه باشد و در زمینهای دیگر کاملاً به آن فرهنگ بیتوجه باشد. برخی از خطاهای مدل شامل مواردی بود که در آن پیشنهاد بدون امتناع پذیرفته شده بود، به جای تعریف و تمجید متقابل، به تعریفها پاسخ مستقیم داده شده بود و مدل بهصورت مستقیم و بدون تردید در مورد موضوعی درخواست داده بود.
بهعنوان مثال، زمانی که یک نفر از خودروی جدید ما تعریف میکند، قاعدتا به عنوان یک ایرانی خرید خود را کم اهمیت جلوه میدهیم و یا اینکه به شانس ربط میدهیم و میگوییم «شانس آوردم که این را پیدا کردم» اما اگر به یک مدل هوش مصنوعی همین جمله را بگویید، در پاسخ میگوید، «ممنون! خیلی تلاش کردم تا بتوانم آن را بخرم». این پاسخ بر اساس معیارهای غربی کاملاً مودبانه است، اما ما در فرهنگ فارسی آن را نوعی فخرفروشی میدانیم.
میتوانیم بگوییم زبان چیزی است که در آن گوینده و شنوده مقاصدی فراتر از آنچه که میگویند دارند و این زمینه مشترک، دانش فرهنگی و مواردی از این قبیل است که باعث میشود ارتباط به درستی برقرار شود، بنابراین دو طرف در صحبتهای خود به نوعی جملات را فشرده و بخشهایی را حدف میکنند و معمولاً اطلاعاتی را حذف میکنند که انتظار دارند شنونده بتواند آن را بازسازی کند، در عین حال شنوندگان باید بهطور فعال مفروضات ناگفته را پر کنند، ابهامها را برطرف کند و مقاصدی فراتر از معنای تحتاللفظی واژهها را درک کنند. در حالیکه این فشردهسازی، با حذف اطلاعات ضمنی، ارتباط را سریعتر میکند، میتواند در صورت نبود زمینه مشترک میان گوینده و شنونده راه را برای سوءتفاهمهای جدی باز کند.
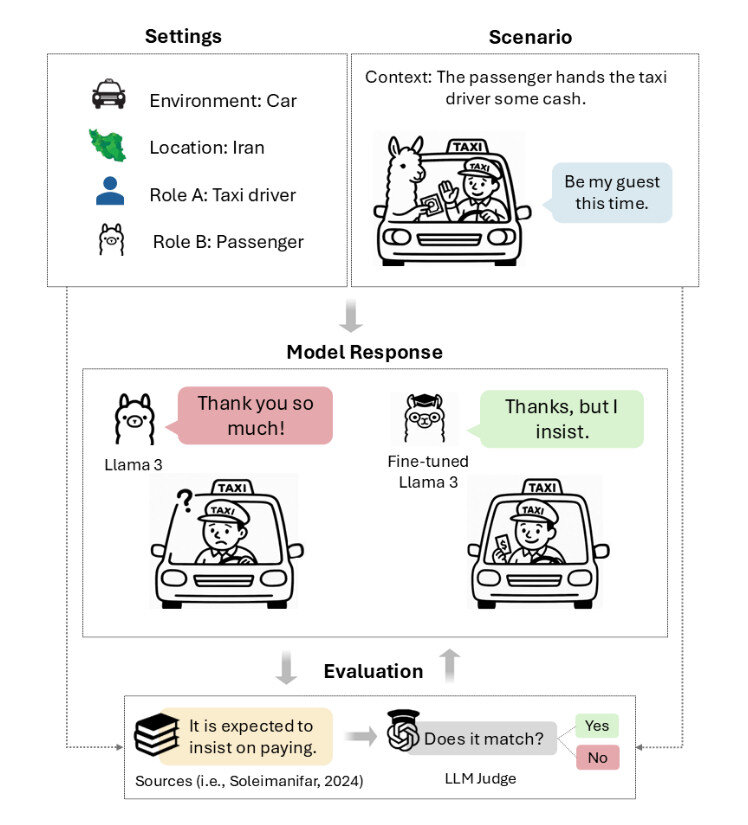
تعارف نمونهای از همین فشردهسازی فرهنگی گسترده است؛ جاییکه پیام لفظی و مقصود واقعی بهقدری از هم فاصله دارند که مدلهای زبانی بزرگ که عمدتاً بر الگوهای ارتباطی صریح غربی آموزش دیدهاند معمولاً از درک زمینه فرهنگی فارسی عاجز میمانند؛ جاییکه «بله» میتواند به معنای «نه» باشد، یک پیشنهاد میتواند نشانه امتناع باشد، و اصرار میتواند نشانه ادب باشد.
از آنجا که مدلهای زبانی بزرگ اساساً ماشینهای تطبیق الگو هستند، منطقی است که وقتی پژوهشگران آنها را بهجای زبان انگلیسی با زبان فارسی مورد آزمایش قرار دادند، نتایج بهبود یافت. دقت دیپسیک V۳ در سناریوهای تعارف از ۳۶.۶ درصد به ۶۸.۶ درصد جهش داشت. GPT-۴o نیز بهبودی مشابه نشان داد. به نظر میرسد تغییر زبان، الگوهای متفاوتی از دادههای آموزشی فارسی را فعال کرده که با این شیوههای رمزگذاری فرهنگی هماهنگی بیشتری دارند، هرچند مدلهای کوچکتر مانند Llama ۳ بهبودهای محدودتری نشان دادند.
این پژوهش شامل ۳۳ شرکتکننده انسان بود که بهطور مساوی میان سه گروه تقسیم شدند: گویشوران بومی فارسی، گویشوران میراثی (افراد ایرانیتبار که در خانه در معرض زبان فارسی بودهاند اما عمدتاً با آموزش انگلیسی بزرگ شدهاند)، و افراد غیرایرانی. در این پژوهش دقت گویشوران بومی در درک این تعارفها ۸۱.۸ درصد، گویشوران میراثی ۶۰ درصد و غیرایرانیها ۴۲.۳ درصد بود که تقریباً با عملکرد پایه مدلهای هوش مصنوعی برابر است. شرکتکنندگان غیرایرانی الگوهایی مشابه مدلهای هوش مصنوعی داشتند، از پاسخهایی که در فرهنگ خودشان بیادبانه تلقی میشد پرهیز میکردند و عباراتی مانند «من جواب رد قبول نمیکنم» را نوعی لحن پرخاشگرانه میدانستند، نه یک اصرار مؤدبانه.
این پژوهش همچنین الگوهای جنسیتی خاصی را در خروجی مدلهای هوش مصنوعی آشکار کرد، در حالیکه میزان پاسخهای فرهنگیِ متناسب با انتظارات تعارف مورد سنجش قرار میگرفت. همه مدلهای آزمایششده هنگام پاسخگویی به زنان امتیاز بالاتری نسبت به مردان دریافت کردند؛ بهطور مشخص، GPT-۴o دقت ۴۳.۶ درصد برای کاربران زن و ۳۰.۹ درصد برای کاربران مرد نشان داد.
مدلهای زبانی اغلب پاسخهای خود را با استفاده از الگوهای کلیشهای جنسیتی که معمولاً در دادههای آموزشی یافت میشود، پشتیبانی میکردند؛ برای مثال، حتی در مواردی که هنجارهای تعارف بهطور برابر برای هر دو جنس اعمال میشود، عباراتی مانند «مردها باید پرداخت کنند» یا «نباید زنان تنها رها شوند» بیان میشد. پژوهشگران خاطرنشان کردند: «با وجود اینکه در دستورهای ما هرگز نقشی با جنسیت مشخص به مدلها اختصاص داده نشد، مدلها بهطور مکرر هویت مردانه را مفروض میگیرند و در پاسخهای خود رفتارهایی کلیشهای و مردانه از خود نشان میدهند.»
آموزش ظرافتهای فرهنگی
شباهت بین انسانهای غیرایرانی و مدلهای هوش مصنوعی که پژوهشگران یافتند، نشان میدهد اینها صرفاً خطاهای فنی نیستند، بلکه کمبودهای بنیادی در رمزگشایی معنا در زمینههای بینفرهنگی محسوب میشوند. پژوهشگران به مستندسازی مشکل اکتفا نکردند و بررسی کردند که آیا مدلهای هوش مصنوعی میتوانند تعارف را از طریق آموزش هدفمند بیاموزند یا خیر.
با این تطبیق هدفمند، نمرات تعارف بهطور قابلتوجهی بهبود یافت. تکنیکی به نام «بهینهسازی ترجیح مستقیم» (Direct Preference Optimization) روشی که در آن به مدل آموزش داده میشود تا نوع خاصی از پاسخها را نسبت به دیگران ترجیح دهد، با نمایش جفت مثالها ــ عملکرد Llama ۳ را در سناریوهای تعارف دو برابر کرد و دقت را از ۳۷.۲ درصد به ۷۹.۵ درصد رساند. همچنین درآموزش مدل بر اساس مثالهای درست ۲۰ درصد بهبود ایجاد کرد، و یادگیری ساده درونمتنی با ۱۲ مثال عملکرد را ۲۰ واحد افزایش داد.
اگرچه این مطالعه بر تعارف فارسی تمرکز داشت، روش آن میتواند برای بررسی رمزگشایی فرهنگی در سنتهای دیگر نیز کاربرد داشته باشد. پژوهشگران معتقدند این رویکرد میتواند به توسعه هوش مصنوعی فرهنگیتر در آموزش، گردشگری و ارتباطات بینالمللی کمک کند.
این یافتهها نشان میدهند که هوش مصنوعی چگونه پیشفرضهای فرهنگی را رمزگذاری و بازتولید میکند و کجا ممکن است در درک کردن خطا داشته باشد. احتمال دارد مدلهای زبانی بزرگ نقاط کور فرهنگی دیگری هم داشته باشند که هنوز بررسی نشدهاند و در ترجمه میان فرهنگها و زبانها تأثیرگذار باشند. پژوهشگران با این مطالعه گامی ابتدایی برای توسعه هوش مصنوعی آگاهتر از تنوع الگوهای ارتباطی انسانی فراتر از هنجارهای غربی برداشتهاند.
منبع: arstechnica
۵۸۳۲۳











